
Introduction
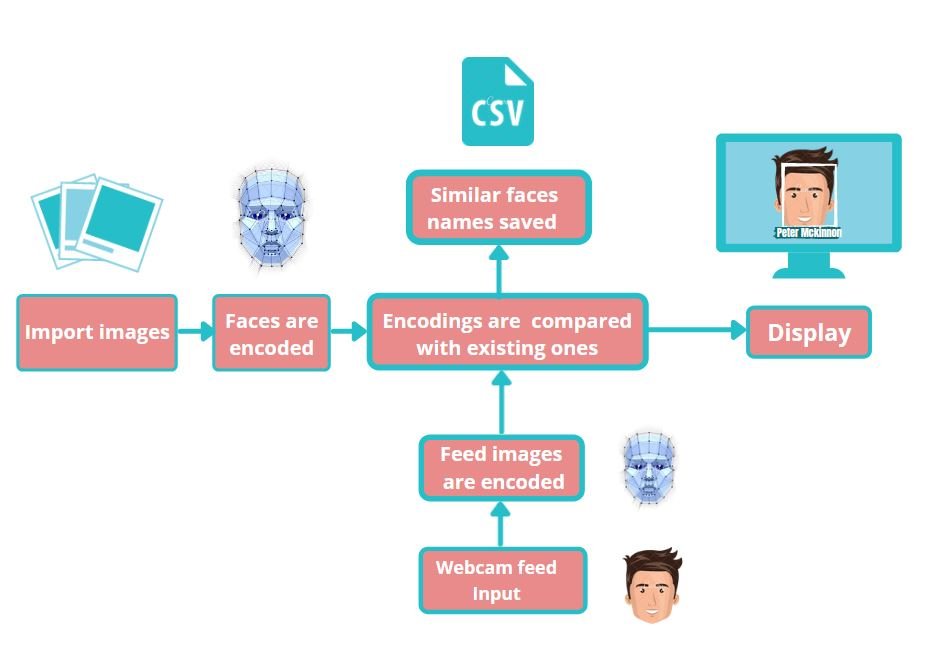
Images input (DATABASE)
face encoding generation
To give you a feel below are the face encodings generated for the input image are the 128-dimensional face encoding.
Cam input
Webcam

COmparision
display
Logging
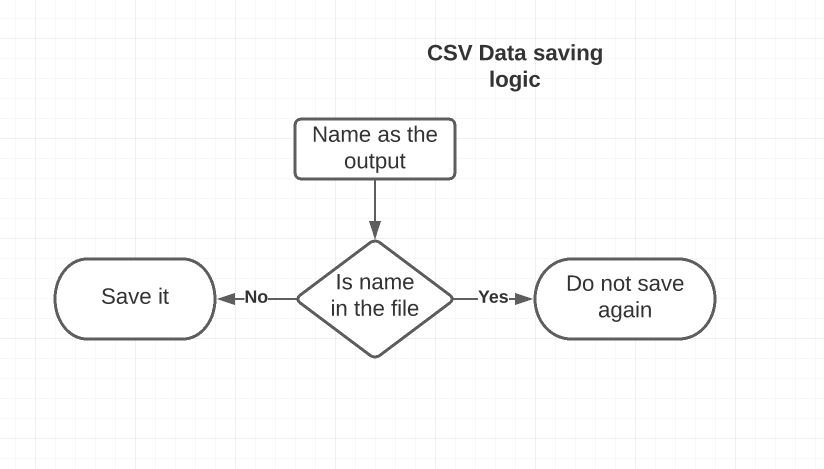
The next iteration of the project will feature automatic CSV file creation at the respective date, with the name as the date. A script is written to generate a new CSV file each day. Furthur we are finding ways to replace the existing CSV file name with the new name.
data logged
Limitations
2. It take for a while for the right name to be settled, which lead to wrong input.
Solutions identified - 20/4
1. The misrepresentation of the images as needed to be removed for that the data set is increased. What I mean by datasets is the number of input images of the people. So here the images are stored in a folder that would be named after the person. The data will be encoded with the name of the person. It was challenging to come up with the code which gets the above two things at a time. I am thinking of using a method where I will save the name of the person (from the file as name) and subsequent encoding. Then we will have another code snippet for another folder. Thus we will have a less complicated code at the end.
2. Second thing I am considering is to set face distance (face distance is Encoding parameters for stored image minus the input image, less the better accuracy) for each of the systems thus to avoid misrepresentation.
3. Another method that I found was on the blog by Adrian from Pyimagesearch who counted the votes for each of the images in the database to come up with the right output.
4. I am also considering appending the results into a list, giving it a maximum range of the output that can be saved in it. Then the name with maximum occurance will be saved as output.
5. Since at the end we are concentrating to identify the face, we can crop the image to make the task smooth for the computer and accumulating the computation time needed.
So now the aim is to implement all this in my improved code.
TIMELINE
Before coming up with a timeline it is necessary to list out the tasks. So below are the identified tasks.
1. Implementing the improved code. Note down the feedback (might have to think about individual value tweaking) (3/5)
2. Final code iteration iteration we are needed to do any. (5/5)
3. Implementing the code on Raspberry Pi. And setting the system for use. (7/5)
4. Finally coming up an enclosure for the system, thus the project can be started for use. (10/5)
Starting point
For implementing and modifying the project, the GitHub repository can be a good starting point. A text file with detailed information is available for the installation of IDE, libraries, and dependencies. A previous blog can be referred to, which has both installation process and code explanation.
Below are some of the resources referred to.
- Background for face_recognition – https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78
- The face recognition library used – https://pypi.org/project/face-recognition/
- The computer vision library – https://pypi.org/project/opencv-python/
- Working with CSV format – https://realpython.com/python-csv/
- Pycharm IDE installation – https://www.youtube.com/watch?v=EpjDOovzgrc
- Useful for installation of libraries if done in command prompt – https://www.youtube.com/watch?v=xaDJ5xnc8dc
- An attendance project for reference – https://www.youtube.com/watch?v=sz25xxF_AVE
- https://www.pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/#download-the-code
The UPDATE - 20/3
After all the challenges incurred during the accuracy with the faces, I realized that the previous values for face distance were 0.6 (Its set default with the module). The advantage of the default face distance is that it fast with face detection. To the idea, the bounding box dynamically moves with our movement, and while on the other hand, it’s prone to assign a wrong name. Secondly, instead of avoiding, it assigns the closest match. I wanted to avoid any peripheral device or external feedback that could end up making the project complicated, so I made the recognization more strict. You can think of face distance as tolerance, the more strict the tolerances are, the better the accuracy. In our case, we have set the tolerance a 0.4. Any Downsides? Yes, the footage seems as if set on lower frame rates. Since we don’t have to do active tracking with face recognition, a 2-3 seconds lag should not matter, unless it hinders our accuracy.
The second change that helped us solve our problem was using multiple photos of the same person. Wait, how to assign the same name for a bunch of images in the database. I have written in our code that once we enter a name, in our .csv file, we don’t want to save it again. It can be avoided by naming the file as ‘Name Surname.01.jpg’ and ‘Name Surname.02.jpg’. Thus we split the name and assigned two distinct encodings with the same name. Results, whenever we needed to unknown face, it would compare faces with the closest matches. Even if fails, in the first case, the second-best is also acceptable.
You might be puzzled about how to decide the number of images per person. Ideally, a single image should be sufficient but in our case, we can’t afford to miss a single chance. So start with maximum images, say, 5/person, then compare the results by reducing the number to one. In most cases, two images are sufficient to get desired results.
THE COde
The code is systematically explained below but if you wish to study the actual code I will share the GitHub link.
iMPOrt libraries
The first step in the program is to import the required libraries. The libraries used are:
cv2 – OpenCV is the huge open-source library for computer vision, machine learning, and image processing and now it plays a major role in real-time operation which is very important in today’s systems.
NumPy – NumPy is a Python library used for working with arrays. It also has functions for working in domain of linear algebra, fourier transform, and matrices. … NumPy stands for Numerical Python.
face_recognition – The face_recognition command lets you recognize faces in a photograph or folder full of photographs. There’s one line in the output for each face. The data is comma-separated with the filename and the name of the person found.
OS – The OS module in Python provides functions for interacting with the operating system. OS comes under Python’s standard utility modules.
datetime – The datetime module supplies classes for manipulating dates and times. While date and time arithmetic is supported, the focus of the implementation is on efficient attribute extraction for output formatting and manipulation. General calendar related functions.
Pyshine – A collection of simple yet high level utilities for Python. The library helps us create quality text for out output.

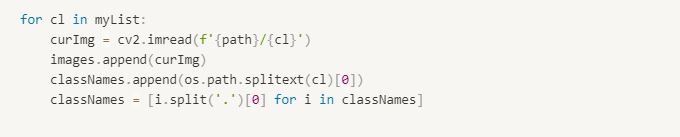
The path for the folders containing the images are defined using the os module.

In order to avoid printing the name with the extension, the split() method splits a string into a list. The code does who things at a time, first removes ex. ‘.jpg’ extension as well the ‘.01’ which helps us to use multiple images with same name.
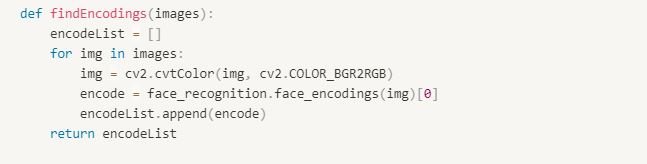
The images are processed to convert them into computer readable format, so we generate face encodings. The face_recognition API generates face encodings for the face found in the images. A face encoding is basically a way to represent the face using a set of 128 computer-generated measurements. Two different pictures of the same person would have similar encoding and two different people would have totally different encoding.
25/3
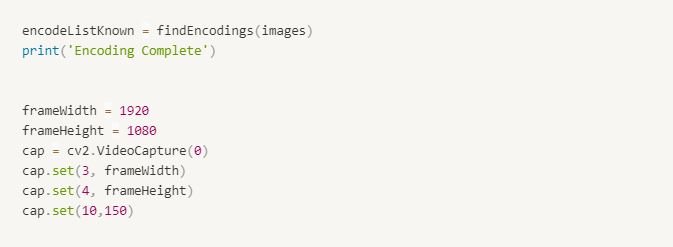
According to the requirement of the program, we cannot overwrite a name once added. The presence of the name is checked before saving it in the file thus if it is already in the file, it won’t be saved. But we require to record attendance on a daily basis. The solution to the problem is to create a new file every day. A new file is generated daily automatically for saving data for that date.

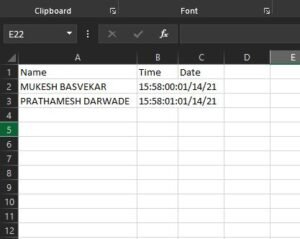
A comma-separated values file is a delimited text file that uses a comma to separate values. Each line of the file is a data record. Each record consists of one or more fields, separated by commas.In our program the data is saved in the following file which can be accessed using excel for data retrival. In the following code the presense of the same is checked, if not present already the data is saved. If someone already recorded comes in front of the camera the data won’t be saved.

The frame size is changed by changing the frameWidth and frameHeight variables.
The data from the webcam is read and converted to RGB format. The face is detected from the frame and encoded. The encoding is sent for comparison with the saved encodings of the images of the people. We have set a sleep of one second since we had noticed earlier that blur faces are also encoded. To discourage this from happening we put a ‘sleep’, so for the next frame, the person is in stable condition.

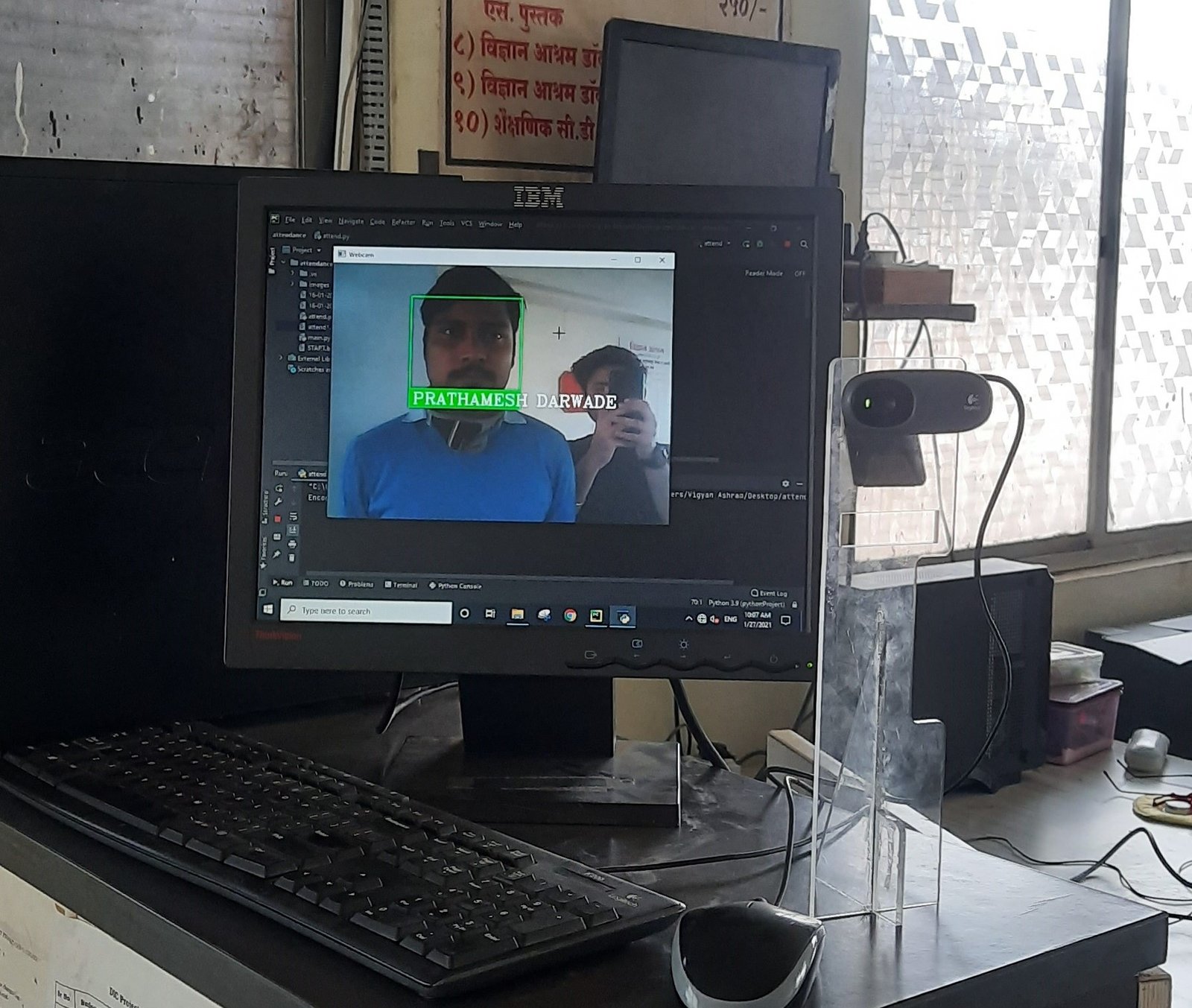
After comparison, if the face distance is checked with the saved names. If the face distance is more than 60% then the name will be displayed. The name is also sent to the def(markAttendance) function, where the name is checked and saved.

To give visual feedback, we show the bounding box in front of the face. We do it using the cv2.rectangle, which creates a bounding box around the face. Here we can select the font for the text and color of the bounding box. The snippet thus helps us to make our code look polished since it’s the only point of contact between the user and the program.

TEsting
The project was tested to see if there any flaws in the system. A lot of times the flaws are only realized when confronted with the during the end user testing scenario. Luckily the flaws were taken into consideration during before the actual testing. So there weren’t much technical issues. The main issues being the hardware of the computer. The data was shared and matched with manually logged data.
Conclusion✨
The project was definitely among my most exciting projects. It was the first time I ever learned a programming language and simultaneously started working on this project. I had a fair share of challenges comprehending the jargon of an esoteric language. But I can now say that this project helped me build a solid foundation which I will surely improve on. But I am happy I can successfully deliver the project as planned.
If I didn’t have a time crunch, I would have worked to find a method of saving the encodings in the place of generating encodings every time. This trick would reduce the processing time. The next thing is automatically starting and stopping the program. I tried it using task scheduler for shutdown and boot RTC settings, but it didn’t work out for the system installed.
I am facing an issue if the number of faces reaches beyond a limit. So solving these minor issues will surely add value to the project.




{kind=link}